Find out how to Make More Deepseek By Doing Less
페이지 정보

본문
DeepSeek 모델 패밀리의 면면을 한 번 살펴볼까요? 이제 이 최신 모델들의 기반이 된 혁신적인 아키텍처를 한 번 살펴볼까요? 이 Lean 4 환경에서 각종 정리의 증명을 하는데 사용할 수 있는 최신 오픈소스 모델이 DeepSeek-Prover-V1.5입니다. 236B 모델은 210억 개의 활성 파라미터를 포함하는 DeepSeek의 MoE 기법을 활용해서, 큰 사이즈에도 불구하고 모델이 빠르고 효율적입니다. 이런 두 가지의 기법을 기반으로, DeepSeekMoE는 모델의 효율성을 한층 개선, 특히 대규모의 데이터셋을 처리할 때 다른 MoE 모델보다도 더 좋은 성능을 달성할 수 있습니다. 기존의 MoE 아키텍처는 게이팅 메커니즘 (Sparse Gating)을 사용해서 각각의 입력에 가장 관련성이 높은 전문가 모델을 선택하는 방식으로 여러 전문가 모델 간에 작업을 분할합니다. 거의 한 달에 한 번 꼴로 새로운 모델 아니면 메이저 업그레이드를 출시한 셈이니, 정말 놀라운 속도라고 할 수 있습니다. 자세한 분석 내용은 Artificial Analysis를 한 번 참조해 보시기 바랍니다. 이렇게 한 번 고르게 높은 성능을 보이는 모델로 기반을 만들어놓은 후, 아주 빠르게 새로운 모델, 개선된 버전을 내놓기 시작했습니다. 이렇게 하면 불필요한 계산에 자원을 낭비하지 않으니 효율이 높아지죠. 이렇게 하면, 모델이 데이터의 다양한 측면을 좀 더 효과적으로 처리할 수 있어서, 대규모 작업의 효율성, 확장성이 개선되죠. 자, 이렇게 창업한지 겨우 반년 남짓한 기간동안 스타트업 DeepSeek가 숨가쁘게 달려온 모델 개발, 출시, 개선의 역사(?)를 흝어봤는데요. 자, 그리고 2024년 8월, 바로 며칠 전 가장 따끈따끈한 신상 모델이 출시되었는데요.
 바로 직후인 2023년 11월 29일, DeepSeek LLM 모델을 발표했는데, 이 모델을 ‘차세대의 오픈소스 LLM’이라고 불렀습니다. ‘DeepSeek’은 오늘 이야기할 생성형 AI 모델 패밀리의 이름이자 이 모델을 만들고 있는 스타트업의 이름이기도 합니다. 현재 출시한 모델들 중 가장 인기있다고 할 수 있는 free deepseek-Coder-V2는 코딩 작업에서 최고 수준의 성능과 비용 경쟁력을 보여주고 있고, Ollama와 함께 실행할 수 있어서 인디 개발자나 엔지니어들에게 아주 매력적인 옵션입니다. 특히 DeepSeek-Coder-V2 모델은 코딩 분야에서 최고의 성능과 비용 경쟁력으로 개발자들의 주목을 받고 있습니다. 역시 중국의 스타트업인 이 DeepSeek의 기술 혁신은 실리콘 밸리에서도 주목을 받고 있습니다. 이 회사의 소개를 보면, ‘Making AGI a Reality’, ‘Unravel the Mystery of AGI with Curiosity’, ‘Answer the Essential Question with Long-termism’과 같은 표현들이 있는데요. 예를 들어 중간에 누락된 코드가 있는 경우, 이 모델은 주변의 코드를 기반으로 어떤 내용이 빈 곳에 들어가야 하는지 예측할 수 있습니다. 과연 DeepSeekMoE는 거대언어모델의 어떤 문제, 어떤 한계를 해결하도록 설계된 걸까요? DeepSeekMoE는 각 전문가를 더 작고, 더 집중된 기능을 하는 부분들로 세분화합니다. Capabilities: DALL·E three is a revolutionary picture generation mannequin. Capabilities: Gemini is a robust generative mannequin specializing in multi-modal content creation, including text, code, and pictures. It excels in creating detailed, coherent images from textual content descriptions. It also supplies a reproducible recipe for creating coaching pipelines that bootstrap themselves by beginning with a small seed of samples and producing increased-high quality training examples because the fashions develop into more capable.
바로 직후인 2023년 11월 29일, DeepSeek LLM 모델을 발표했는데, 이 모델을 ‘차세대의 오픈소스 LLM’이라고 불렀습니다. ‘DeepSeek’은 오늘 이야기할 생성형 AI 모델 패밀리의 이름이자 이 모델을 만들고 있는 스타트업의 이름이기도 합니다. 현재 출시한 모델들 중 가장 인기있다고 할 수 있는 free deepseek-Coder-V2는 코딩 작업에서 최고 수준의 성능과 비용 경쟁력을 보여주고 있고, Ollama와 함께 실행할 수 있어서 인디 개발자나 엔지니어들에게 아주 매력적인 옵션입니다. 특히 DeepSeek-Coder-V2 모델은 코딩 분야에서 최고의 성능과 비용 경쟁력으로 개발자들의 주목을 받고 있습니다. 역시 중국의 스타트업인 이 DeepSeek의 기술 혁신은 실리콘 밸리에서도 주목을 받고 있습니다. 이 회사의 소개를 보면, ‘Making AGI a Reality’, ‘Unravel the Mystery of AGI with Curiosity’, ‘Answer the Essential Question with Long-termism’과 같은 표현들이 있는데요. 예를 들어 중간에 누락된 코드가 있는 경우, 이 모델은 주변의 코드를 기반으로 어떤 내용이 빈 곳에 들어가야 하는지 예측할 수 있습니다. 과연 DeepSeekMoE는 거대언어모델의 어떤 문제, 어떤 한계를 해결하도록 설계된 걸까요? DeepSeekMoE는 각 전문가를 더 작고, 더 집중된 기능을 하는 부분들로 세분화합니다. Capabilities: DALL·E three is a revolutionary picture generation mannequin. Capabilities: Gemini is a robust generative mannequin specializing in multi-modal content creation, including text, code, and pictures. It excels in creating detailed, coherent images from textual content descriptions. It also supplies a reproducible recipe for creating coaching pipelines that bootstrap themselves by beginning with a small seed of samples and producing increased-high quality training examples because the fashions develop into more capable.
Multilingual training on 14.8 trillion tokens, closely centered on math and programming. deepseek ai’s system: The system is called Fire-Flyer 2 and is a hardware and software program system for doing large-scale AI coaching. He monitored it, in fact, utilizing a industrial AI to scan its traffic, offering a continuous abstract of what it was doing and guaranteeing it didn’t break any norms or laws. Note that using Git with HF repos is strongly discouraged. Up until this point, High-Flyer produced returns that have been 20%-50% greater than inventory-market benchmarks in the past few years. It’s backed by High-Flyer Capital Management, a Chinese quantitative hedge fund that uses AI to inform its buying and selling decisions. It’s on a case-to-case foundation depending on the place your impact was at the previous firm. "Innovation usually arises naturally - it’s not something that may be deliberately deliberate or taught," he stated. If talking about weights, weights you'll be able to publish immediately. We focus the majority of our NPU optimization efforts on the compute-heavy transformer block containing the context processing and token iteration, whereby we employ int4 per-channel quantization, and selective combined precision for the weights alongside int16 activations.
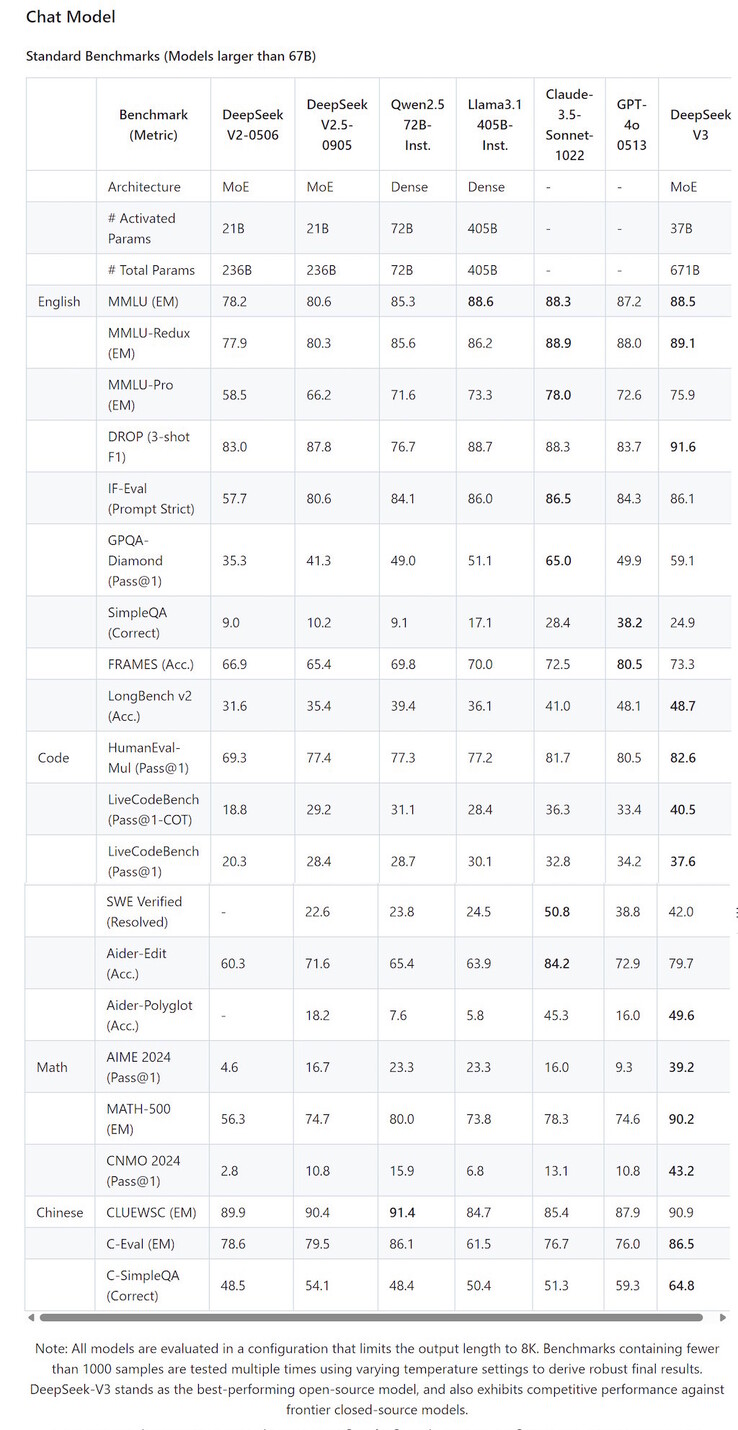 The analysis results underscore the model’s dominance, marking a major stride in natural language processing. The model’s open-source nature also opens doorways for additional analysis and development. Sources: AI analysis publications and opinions from the NLP neighborhood. Unlike most teams that relied on a single mannequin for the competitors, we utilized a twin-model method. This approach allows for more specialised, correct, and context-aware responses, and sets a new standard in handling multi-faceted AI challenges. In standard MoE, some consultants can become overly relied on, while other experts may be rarely used, losing parameters. 2024-04-15 Introduction The goal of this post is to deep-dive into LLMs which might be specialized in code era tasks and see if we will use them to write code. Innovations: Mixtral distinguishes itself by its dynamic allocation of tasks to the most fitted specialists inside its network. free deepseek-Coder-V2 is an open-supply Mixture-of-Experts (MoE) code language model that achieves performance comparable to GPT4-Turbo in code-particular duties. 1: MoE (Mixture of Experts) 아키텍처란 무엇인가? Some consultants imagine this collection - which some estimates put at 50,000 - led him to construct such a powerful AI model, by pairing these chips with cheaper, less sophisticated ones.
The analysis results underscore the model’s dominance, marking a major stride in natural language processing. The model’s open-source nature also opens doorways for additional analysis and development. Sources: AI analysis publications and opinions from the NLP neighborhood. Unlike most teams that relied on a single mannequin for the competitors, we utilized a twin-model method. This approach allows for more specialised, correct, and context-aware responses, and sets a new standard in handling multi-faceted AI challenges. In standard MoE, some consultants can become overly relied on, while other experts may be rarely used, losing parameters. 2024-04-15 Introduction The goal of this post is to deep-dive into LLMs which might be specialized in code era tasks and see if we will use them to write code. Innovations: Mixtral distinguishes itself by its dynamic allocation of tasks to the most fitted specialists inside its network. free deepseek-Coder-V2 is an open-supply Mixture-of-Experts (MoE) code language model that achieves performance comparable to GPT4-Turbo in code-particular duties. 1: MoE (Mixture of Experts) 아키텍처란 무엇인가? Some consultants imagine this collection - which some estimates put at 50,000 - led him to construct such a powerful AI model, by pairing these chips with cheaper, less sophisticated ones.
If you loved this short article and you would like to receive a lot more information regarding ديب سيك مجانا kindly go to the web-site.
- 이전글تركيب زجاج واجهات والومنيوم 25.02.01
- 다음글Sick And Bored with Doing Deepseek The Old Way? Read This 25.02.01
댓글목록
등록된 댓글이 없습니다.